
Microsoft’s Phi-3.5, the latest release in its family of open-weights, small language models, has the industry buzzing. The lineup—comprising Phi-3.5 Mini, Phi-3.5 MoE, and Phi-3.5 Vision—punch well above their weight in performance benchmarks.
Phi-3.5 Mini, with its 3.8 billion parameters, outshines larger models like Llama 3.1 8B and Mistral 7B in multilingual capabilities. This model is particularly suited for scenarios requiring strong reasoning capabilities in resource-constrained environments.
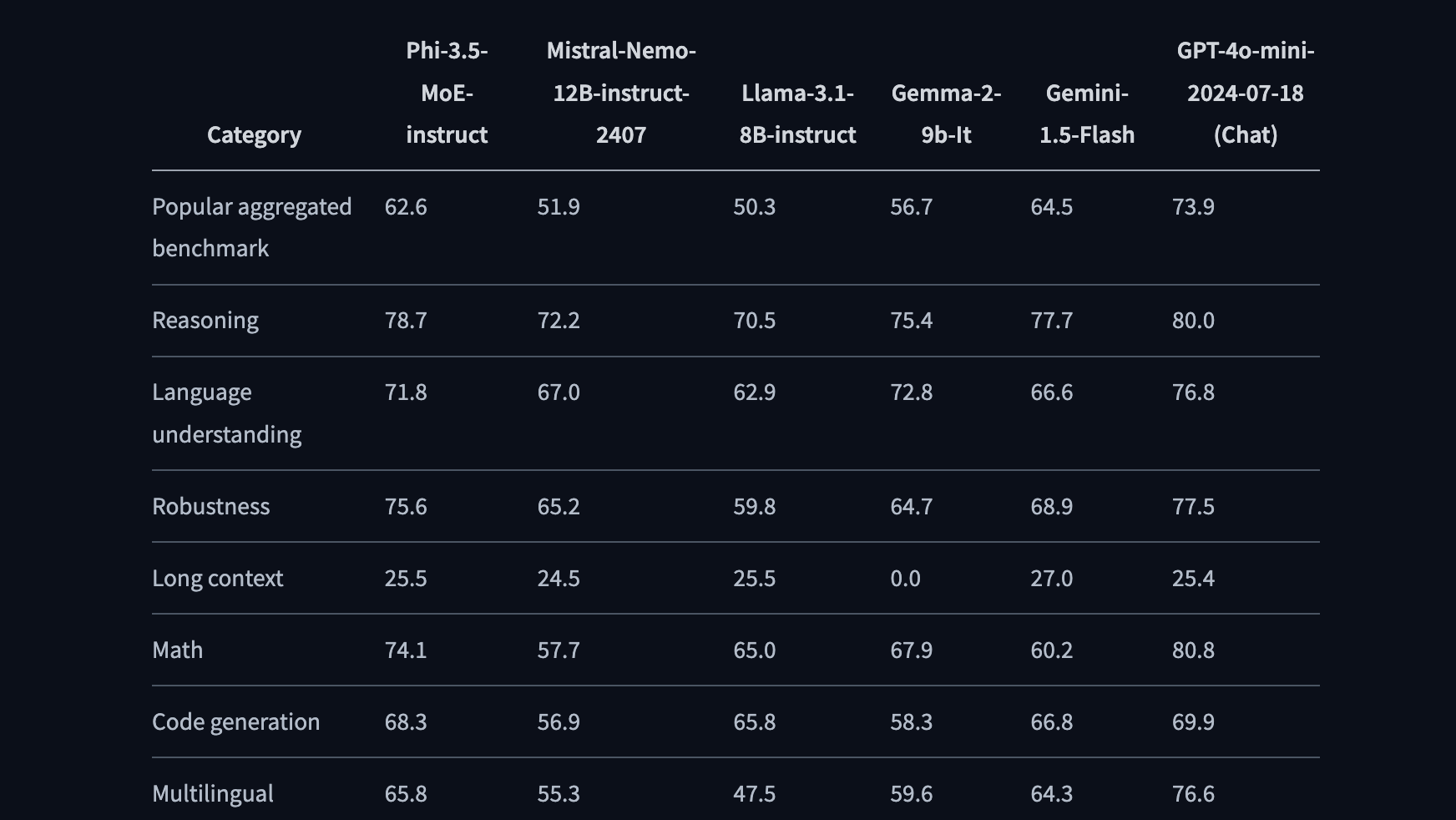
The Mixture of Experts (MoE) model has 42 billion total parameters but only 6.6 billion are active during generation. This efficiency allows it to surpass competitors like Google's Gemini 1.5 Flash in reasoning tasks, while maintaining a smaller computational footprint. The modular approach of the MoE architecture also means that this model can dynamically switch between different “experts” depending on the task at hand, ensuring both efficiency and accuracy in complex scenarios.
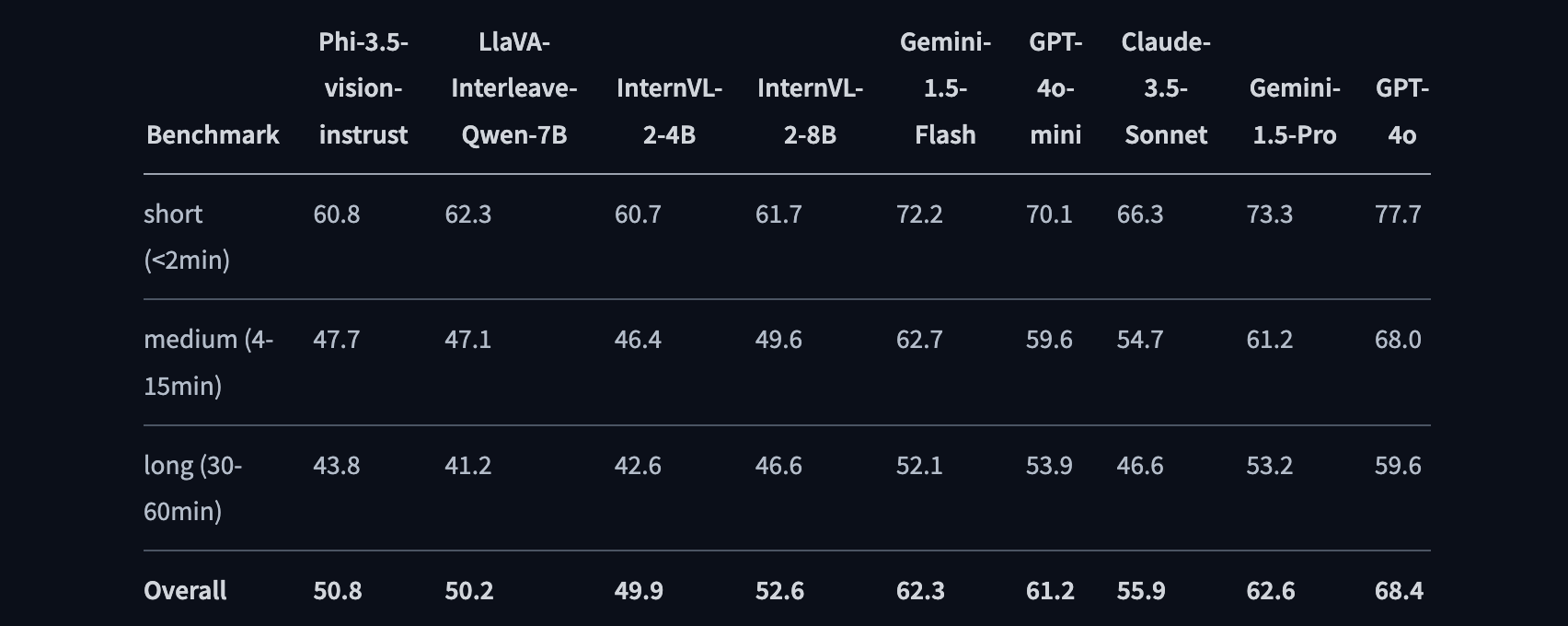
Rounding out the lineup is Phi-3.5 Vision, which integrates multimodal capabilities, processing both text and images. With 4.2 billion parameters, it excels at tasks like optical character recognition, chart comprehension, and even video summarization. Trained on a mixture of synthetic and curated public data, Phi-3.5 Vision offers state-of-the-art performance in image-heavy tasks that traditionally require much larger models. Its ability to handle multi-frame reasoning tasks—like comparing images from different time points or summarizing a sequence of frames—puts it on par with much larger competitors, such as GPT-4o.
A standout feature across all three models is their 128,000 token context length. This extensive context window enables the models to handle long documents, complex conversations, and multi-frame visual analysis with ease.
Microsoft’s dual strategy of advancing both larger models, like those in the GPT family, and smaller, more efficient models, like the Phi series, showcases its nuanced approach to AI development. Where larger models are essential for orchestrating complex, cloud-based tasks, these smaller models are opening new doors for AI to be deployed at the edge—in offline environments and on smaller devices. This not only broadens the scope of where and how AI can be applied but also makes cutting-edge AI more accessible across industries, from agriculture to manufacturing to healthcare.
All three Phi-3.5 models are available on Hugging Face under a permissive, open-source MIT license. Developers can freely use, modify, and commercialize them.