
NVIDIA has unveiled TensorRT-LLM, an open-source library that accelerates and optimizes inference performance on the latest large language models (LLMs) on NVIDIA Tensor Core GPUs. With the proliferation of massive language models like Meta's Llama 2 and applications like conversational AI exploding, efficiently running these giant neural networks in production has become a major challenge.
TensorRT-LLM aims to significantly boost LLM throughput and cut costs by taking advantage of NVIDIA's latest data center GPUs. It wraps TensorRT’s Deep Learning Compiler, optimized kernels from FasterTransformer, pre- and post-processing, and multi-GPU/multi-node communication in a simple, open-source Python API for defining, optimizing, and executing LLMs for inference in production.
NVIDIA developed TensorRT-LLM working closely with leading companies in the AI ecosystem, including Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (acquired by Databricks), OctoML, Tabnine, and Together AI. This has enabled them to build key optimizations and features into TensorRT-LLM that target the real-world needs of organizations deploying LLMs.
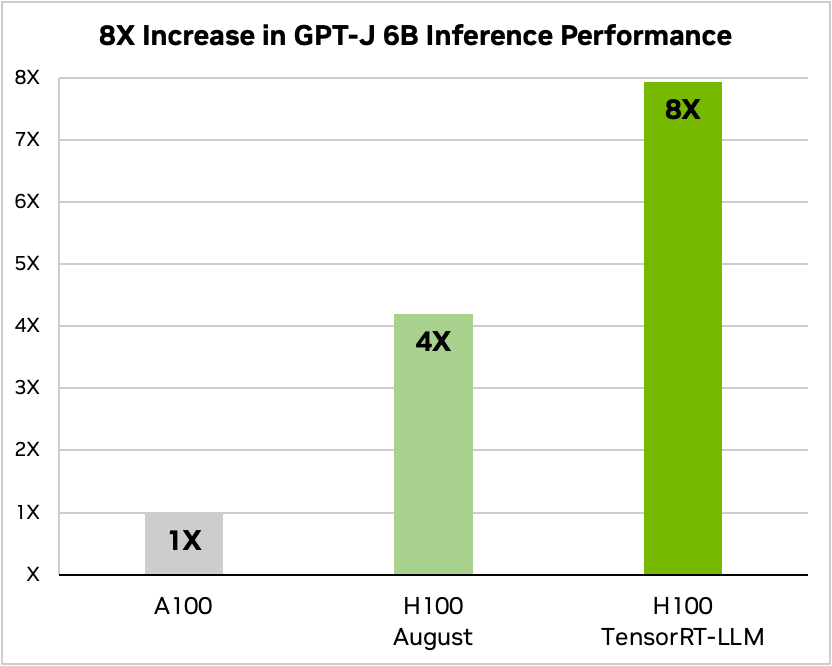
The performance metrics are startlingly impressive. Benchmarks show that when TensorRT-LLM is paired with NVIDIA H100, there is an 8x increase in performance in tasks like article summarization compared to the A100.
For developers, NVIDIA provides an easy-to-use, open-source, and modular Python API for customizing, optimizing, and deploying new LLMs without needing deep C++ or CUDA expertise. Companies like MosaicML have already found it easy to add their specific features atop the TensorRT-LLM framework, echoing the general sentiment that the software is an "absolute breeze" to use.
The library incorporates sophisticated features like paged-attention, quantization, and more, to push the envelope on what's possible with LLM serving. With the ability to convert model weights into a new FP8 format easily, NVIDIA H100 GPUs with TensorRT-LLM are enabling radical reductions in memory consumption without sacrificing model accuracy. This makes it possible to run larger and more complicated models on the same hardware, a factor that could significantly influence the direction of AI development and deployment across sectors.
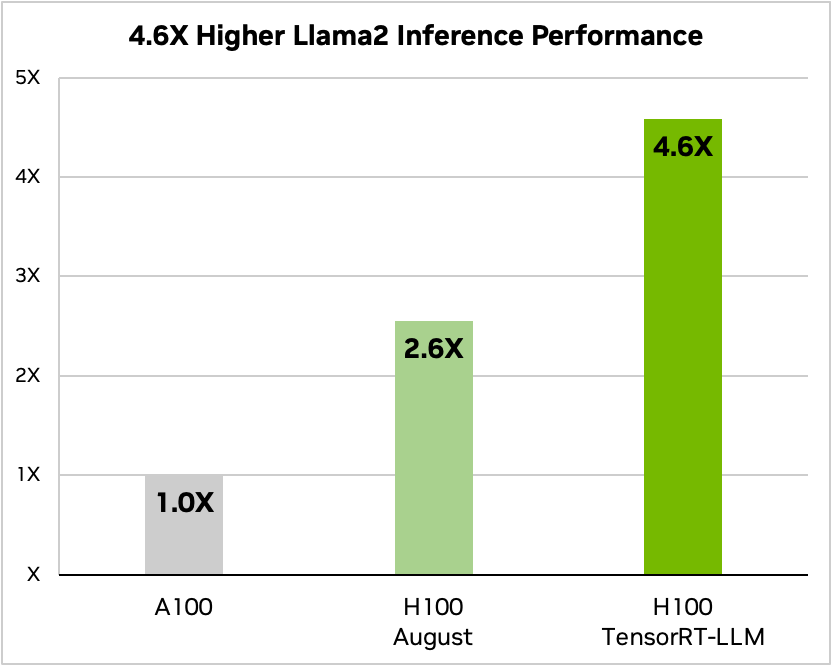
TensorRT-LLM empowers an increasingly diverse LLM ecosystem. With the advent of massive models like Meta's 70-billion-parameter Llama 2, or Falcon 180B, a one-size-fits-all approach is simply infeasible. These models often require multi-GPU setups and intricate coordination for real-time performance. TensorRT-LLM simplifies this by offering tensor parallelism that distributes weight matrices across devices, removing the need for manual fragmentation and reorganization by developers.
Another salient feature is the in-flight batching optimization, designed to efficiently manage the highly variable workloads common in LLM applications. Whether it’s question-and-answer interactions in a chatbot or a document summarization task, this feature allows for dynamic parallel execution, thereby maximizing GPU usage. As a result, enterprises can expect minimized total cost of ownership (TCO), a crucial factor given the growing scale and scope of AI deployments.
As new models and model architectures are introduced, developers can optimize their models with the latest NVIDIA AI kernels available open source in TensorRT-LLM. The supported kernel fusions include cutting-edge implementations of FlashAttention and masked multi-head attention for the context and generation phases of GPT model execution, along with many others.
In addition to its adaptability, TensorRT-LLM also comes preloaded with fully optimized, ready-to-run versions of several of the most impactful large language models in use today. This library includes big names like Meta's Llama 2, OpenAI's GPT-3, Falcon, Mosaic MPT, and BLOOM, among others.
The incorporation of these features—easy adaptability to new models and pre-optimized versions of existing models—demonstrates how TensorRT-LLM isn't just another tool; it's a comprehensive platform designed to empower developers and accelerate the deployment of LLMs across a variety of applications and industries.
With the use of LLMs continuing to grow exponentially and powering everything from conversational assistants to creative tools, optimized inference performance is critical for productive adoption.
Registered developers in NVIDIA's Developer Program can now apply for early access release. The company says general availability is expected in the coming weeks.