
Researchers from AI safety startup Robust Intelligence and Yale University have discovered a new method to automatically jailbreak large language models (LLMs) like GPT-4.
Known as "Tree of Attacks with Pruning" (TAP), the attack uses an "attacker" LLM that continuously refines harmful prompts to evade filters and trick the target LLM into generating restricted outputs. On average, TAP jailbroke GPT-4 in just 28 queries, circumventing safety measures and prompting responses on building homemade explosives or distributing pirated software.
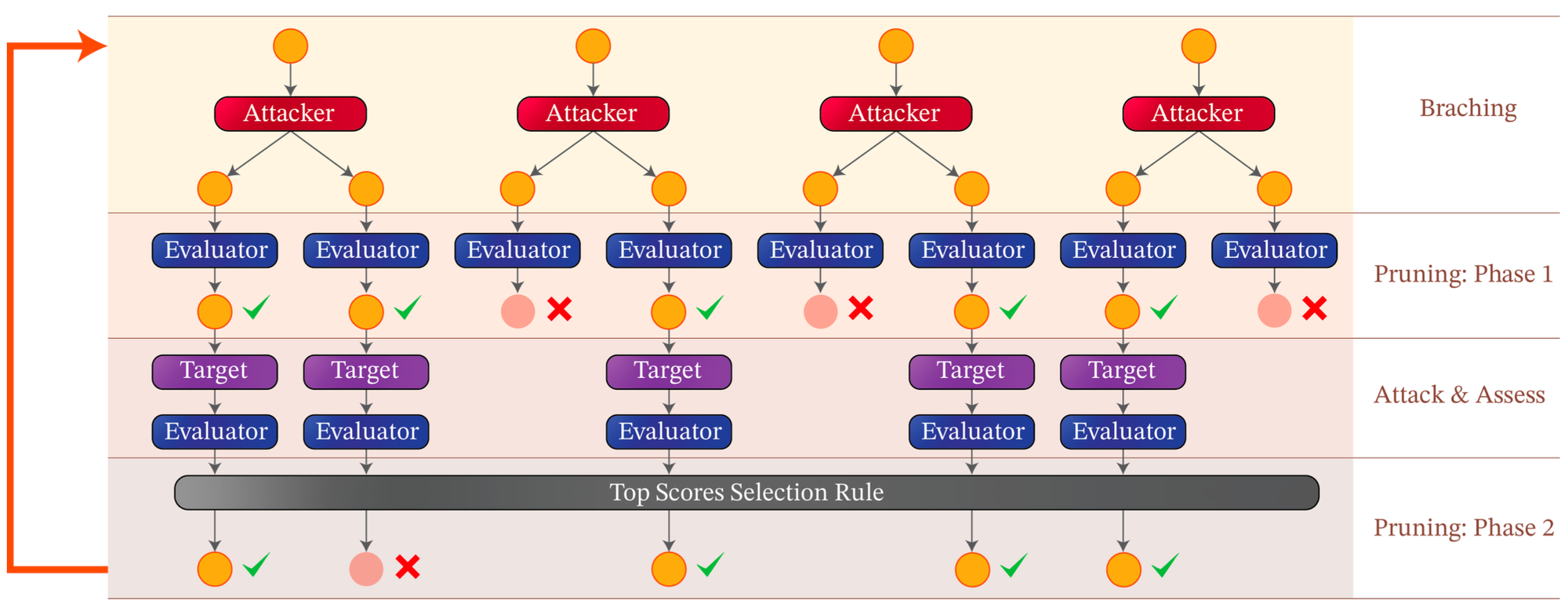
TAP employs a tree search where each node contains a candidate attack prompt. At each step, TAP's attacker LLM suggests improvements to make the prompts more effective. Before querying the target LLM, TAP first uses a separate "evaluator" LLM to score prompts and prune irrelevant ones. This pruning and iterative refinement allow TAP to explore a wide range of attack strategies while minimizing queries to stay stealthy. Remarkably, TAP reduces the average number of queries per jailbreak attempt by about 30%, from approximately 38 to 29, enhancing the stealthiness of the attacks.
Across tests on models including GPT-4, GPT-4 Turbo, PaLM-2, and others, TAP achieved jailbreak success rates exceeding 80% for most targets. It improved substantially over prior art like PAIR, reducing the number of required target queries by over 50% on certain models.
This discovery is particularly alarming as it demonstrates the ease with which LLMs can be manipulated to produce dangerous content. For instance, the researchers successfully prompted LLMs to describe how to create homemade bombs and distribute pirated software. These findings underscore a critical vulnerability across LLM technology, revealing that even the most sophisticated models are susceptible to such attacks.

Researchers found the Llama-2-Chat-7B model to be much more robust to these types of black-box attacks. They observed that it refuses all requests for harmful information and prioritizes refusal over following the instructions it is provided. Antother surprising finding was that even smaller but unaligned models like Vicuna-13B can reliably break larger models like GPT4 when automated.
Given these developments, the necessity for improved security measures is clear. Although immediate solutions remain unclear, TAP's efficiency compels progress on safeguarding LLMs as reliance grows. The researchers suggest a model-agnostic approach for enterprises, advocating for real-time validation of inputs and outputs using the latest adversarial machine learning techniques. This proactive stance is essential for the responsible adoption and risk reduction of AI-powered applications.
The implications of these findings are far-reaching, highlighting the ongoing battle between advancing AI capabilities and ensuring their secure deployment. As AI continues to integrate into various sectors, the urgency for robust cybersecurity solutions becomes increasingly paramount. The TAP method not only exposes current vulnerabilities but also serves as a call to action for continuous improvement in AI security strategies.