Last week, French startup, Mistral AI not only raised $415 million, but dropped a fancy new sparse mixture of experts model, Mixtral-8x7B, and announced the beta launch of it's new platform services.
Mixtral-8x7B outperforms the Llama 2 70B model in most benchmarks while delivering six times faster inference. Plus, it's an open-weights model released with an Apache 2.0 license, meaning anyone can access and use it for their own projects.
In this article, I'll cover the best ways to get started with Mixtral-8x7B. Let's dive in!
Directly From the Source
If you are an experienced researcher/developer, it goes without saying that you can download the torrent directly using the maginet link that Mistral has provided. This download includes Mixtral 8x7B and Mixtral 8x7B Instruct.
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce
RELEASE a6bbd9affe0c2725c1b7410d66833e24Use Mistral AI Platform
If you haven't already done so, now is probable a good time to sign up for beta access to Mistral's AI platform where you will be able to easily access the models via API. If you have a business use-case, just reach out to the company, the Mistral team will work with you and accelerate access. N.B. The Mixtral-8x7B model is available behind the mistral-small endpoint. As a bonus, you'll also get access to mistral-medium, their most powerful model yet.
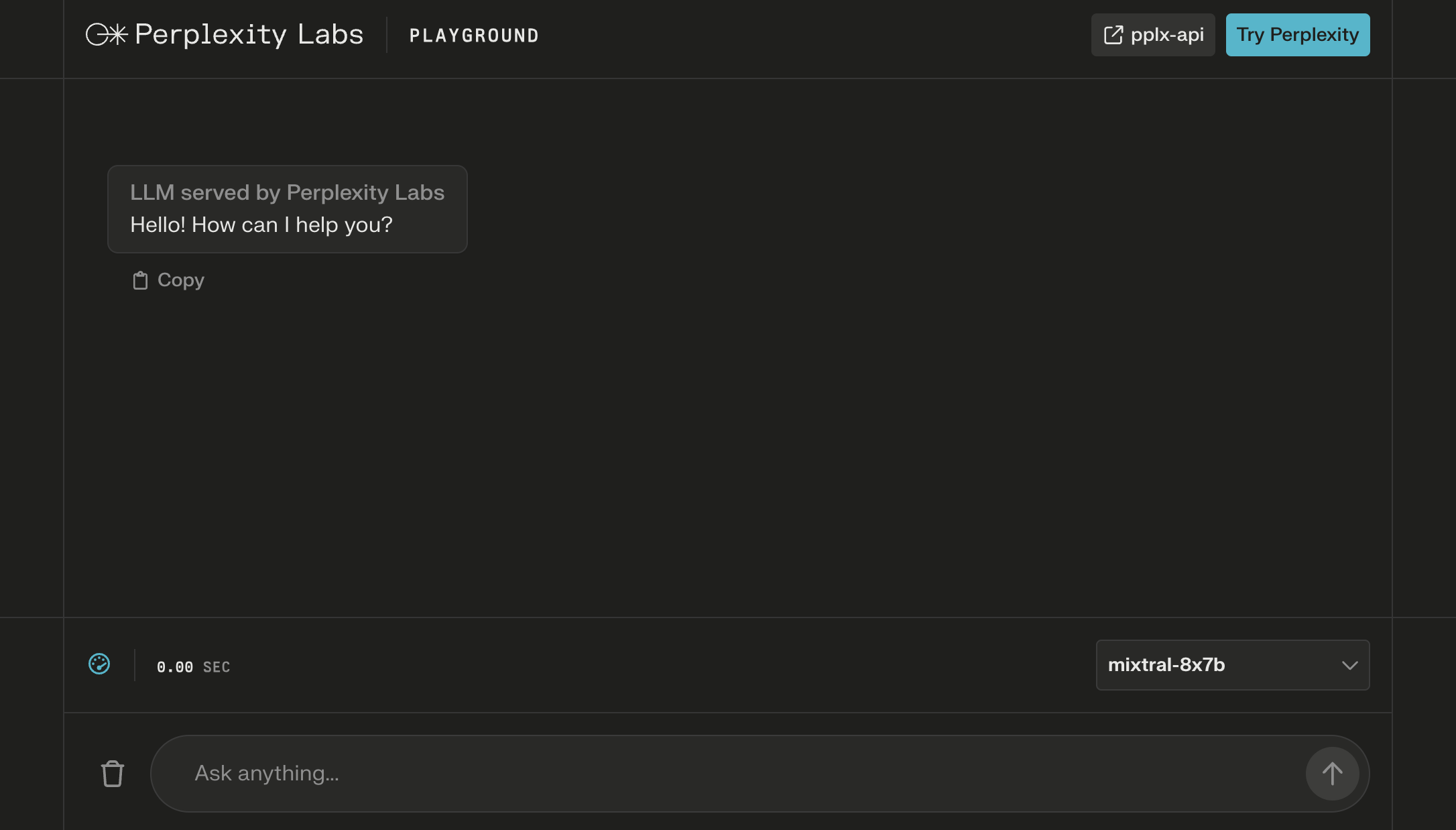
Use Perplexity Labs
If you want to simply use the instruction tuned version via a chat interface, you can use the Perplexity Labs playground. Just choose it from the model selection dropdown in the bottom right corner.
Use Hugging Face
Hugging Face has both the base model and the instruction fine-tuned model which can be used for chat-based inference.
There are ready-to-use checkpoints that can be downloaded and used via the HuggingFace Hub or you can convert the raw checkpoints to the HuggingFace format. Read this for detailed instructions including loading and running the model using Flash Attention 2.
The Mixtral-8x7B-Instruct-v0.1 model is also available on Hugging Face Chat. Simply select it as your model of choice.
Use Together.AI
Together provides one of the fastest inference stacks via API. These are the folks behind FlashAttention after all.
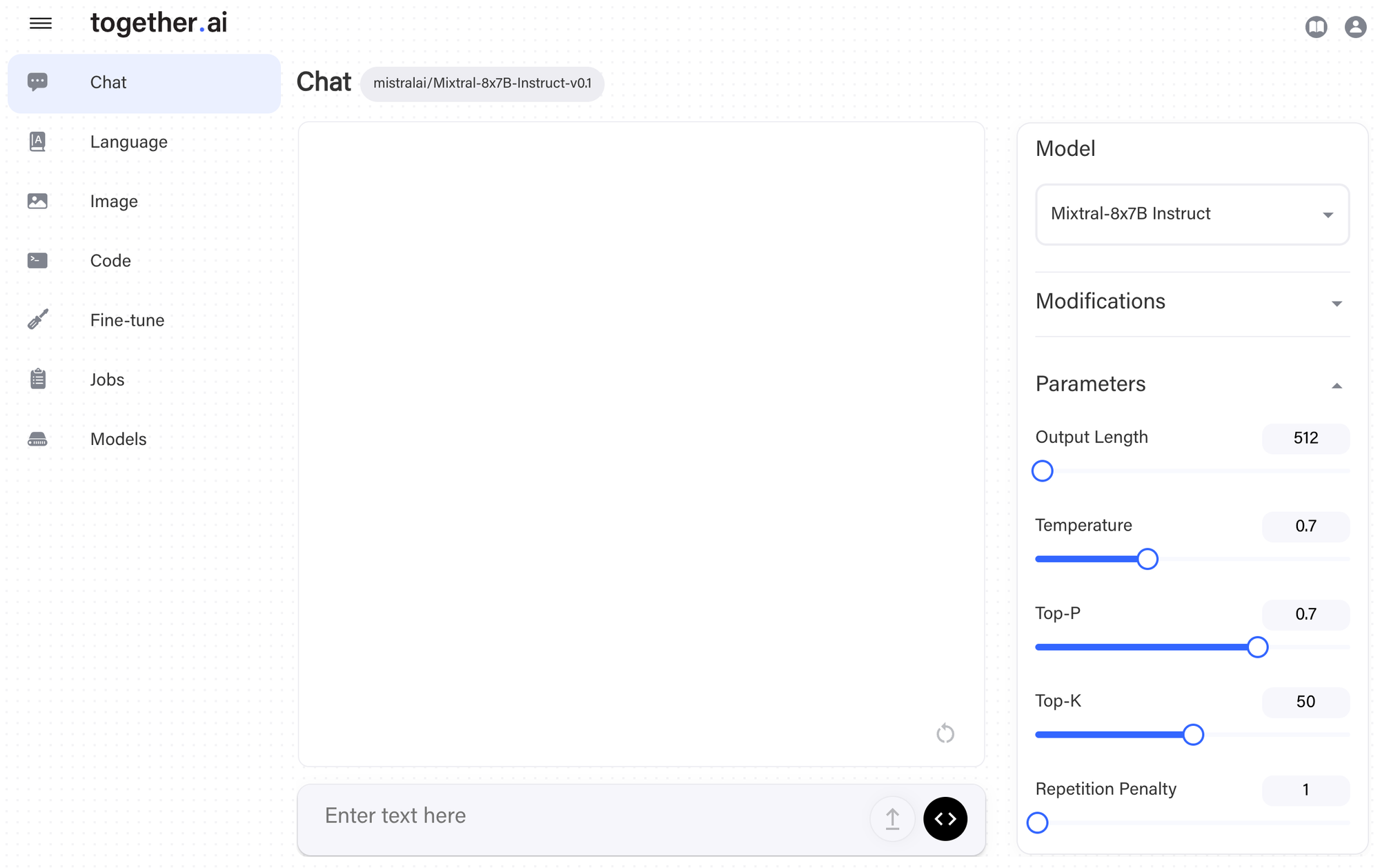
They have optimized the Together Inference Engine for Mixtral and it is available at up to 100 token/s for $0.0006/1K tokens. You can access DiscoLM-mixtral-8x7b-v2 and Mixtral-8x7b via the playground or via their API. See instructions here.
Use Fireworks Generative AI Platform
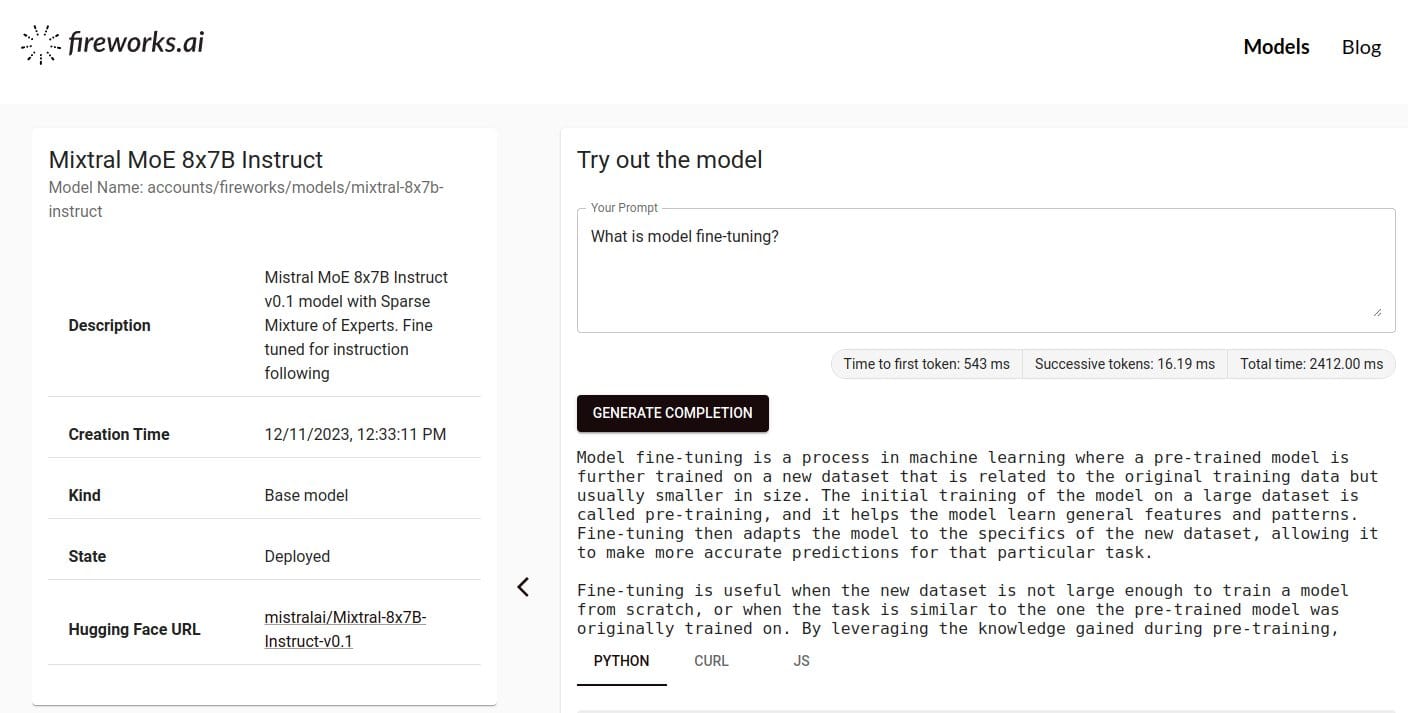
Fireworks is another handy option. The platform aims to bring fast, affordable, and customizable open LLMs to developers. Once you log in, just search for the mixtral-8x7b-instruct model to get started.
N.B., you can also access models hosted by Fireworks via other platforms like Vercel.
Run it Locally with LM Studio
LM Studio is one of the easiest ways to run models offline locally on your Mac, Windows or Linux computers. LM Studio is made possible thanks to the llama.cpp project and supports any ggml Llama, MPT, and StarCoder model on Hugging Face.
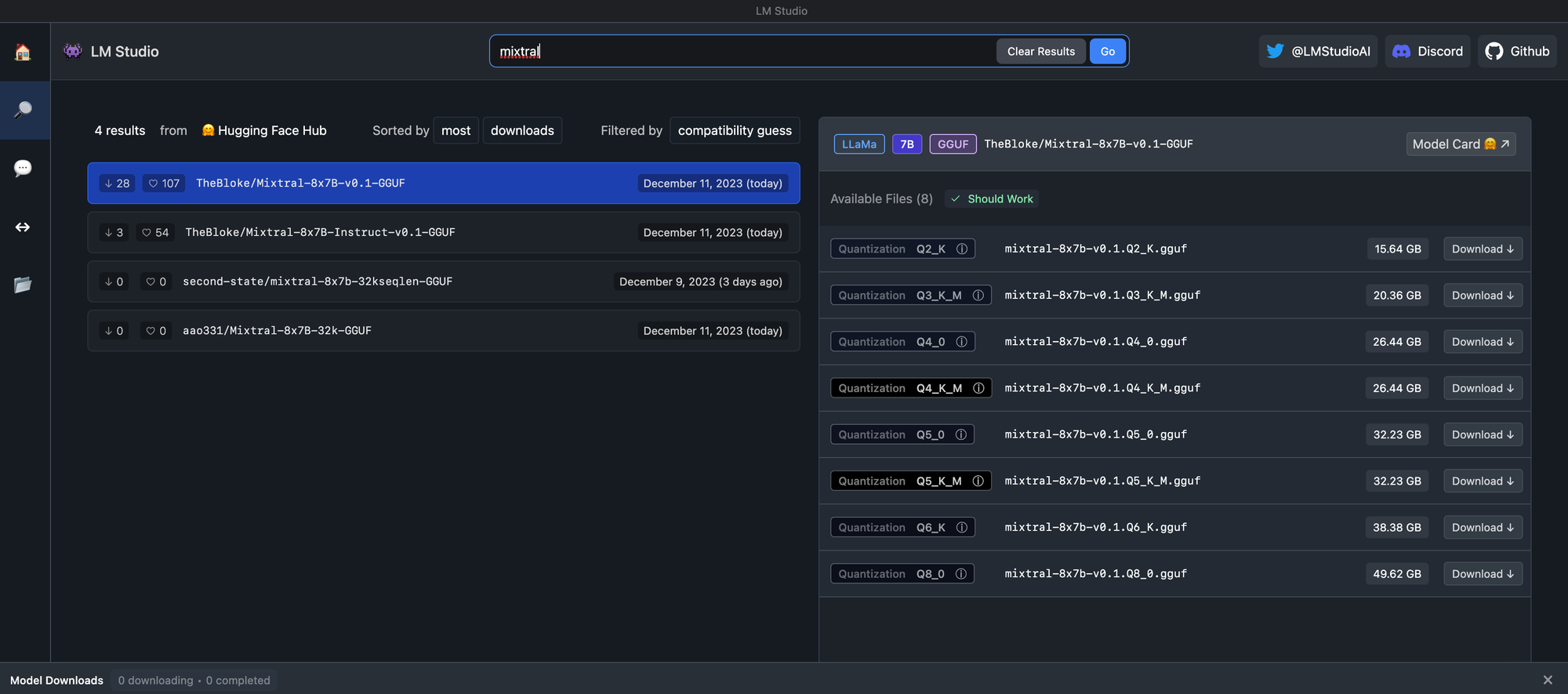
Simply download and install LM Studio then search for Mixtral to find compatible versions.
Run it Locally with Ollama
Ollama is an easy way for you to run large language models locally on macOS or Linux. Simply download Ollama and run one of the following command in your CLI of choice.
ollama run mixtralN.B. Mixtral requires 48GB of RAM to run smoothly. By default, this will be allow you to chat with the model. If you'd like to go further (like using your own data), Ollama has provided detailed instructions on how to use LlamaIndex to create a completely local, open-source retrieval-augmented generation (RAG) app complete with an API.