
Please note that this article has been updated to include a link to the latest resources to get started with Mixtral-8x7B.
Mistral AI, a new AI research startup, has open-sourced Mistral 7B, a 7.3 billion parameter model that achieves state-of-the-art performance compared to other models of similar size. Available under the permissive Apache 2.0 license, Mistral 7B represents a remarkable achievement in open and free access to powerful AI.
In benchmarks, Mistral 7B beats Meta's Llama 2 13B model while approaching the scores of Llama's massive 70B parameter version. This is despite being almost twice as small as Llama 2 13B.
Here's how you can quickly get started with Mistral 7B locally or in your preferred cloud:
Directly From the Source
If you are an experienced researcher/developer, you can download the model and grab ready-to-use Docker images on Mistral AI's Github registry. The weights are distributed separately.
magnet:?xt=urn:btih:208b101a0f51514ecf285885a8b0f6fb1a1e4d7d&dn=mistral-7B-v0.1&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=https%3A%2F%http://2Ftracker1.520.jp%3A443%2Fannounce
RELEASE ab979f50d7d406ab8d0b07d09806c72cN.B. To run the image, you need a cloud virtual machine with at least 24GB of vRAM for good throughput and float16 weights. Other inference stacks can lower these requirements to 16GB vRAM. Here's the quickstart guide.
Run Locally with Ollama
Ollama is an easy way for you to run large language models locally on macOS or Linux. Simply download Ollama and run one of the following commands in your CLI.
For the default Instruct model:
ollama run mistral
For the text completion model:
ollama run mistral:textN.B. You will need at least 8GB of RAM. You can find more details on the Ollama Mistral library doc.
Hugging Face Inference Endpoints
With Hugging Face Inference Endpoints, you can easily deploy models on dedicated, fully managed infrastructure. It is a cheap, secure, compliant and flexible production solution.
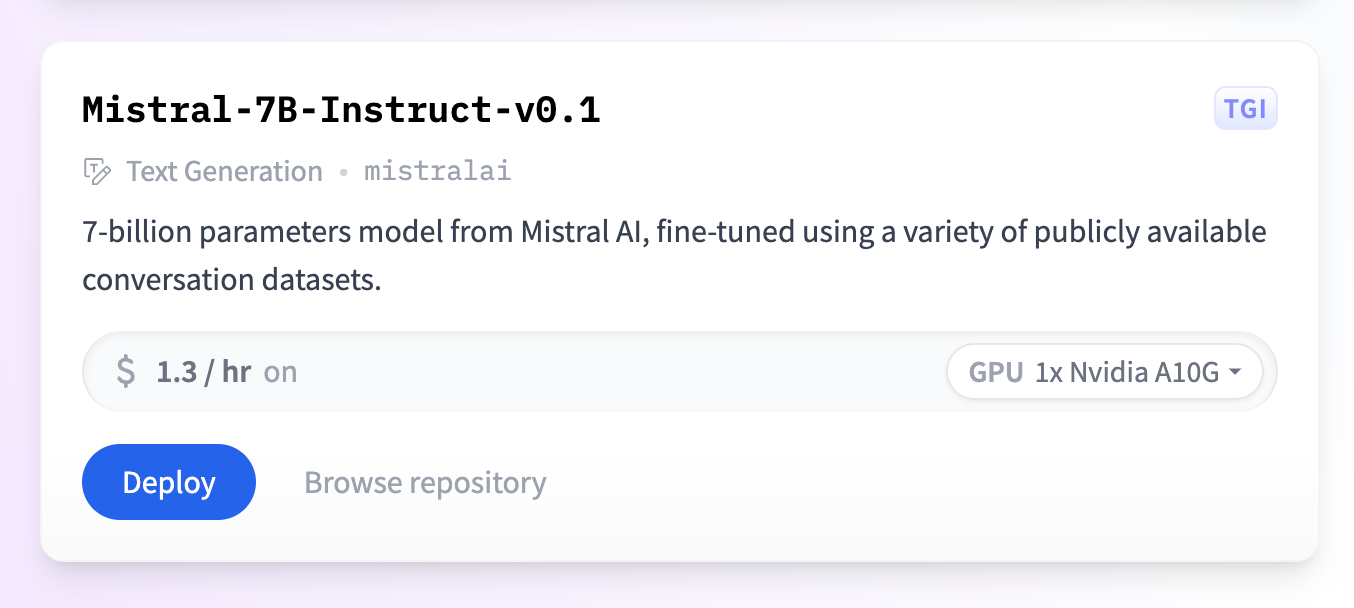
For example, you can deploy Mistral 7B (it's a 1-click deployment from the Model catalog) for about $1.30/hour. It runs on a single NVIDIA A10G GPU with 33ms/token using Text Generation Inference.
Perplexity Mistral Chat
Perplexity AI is a conversational AI search engine that delivers answers to questions using various language models. Simply choose mistral-7b-intsruct from the model selection dropdown to get started.
N.B. Mistral 7B is a pretrained base model and therefore does not have any moderation mechanisms, i.e., it is fully uncensored.
With Skypilot on Any Cloud
SkyPilot is a framework for running LLMs, AI, and batch jobs on any cloud, offering maximum cost savings, highest GPU availability, and managed execution. Follow these instructions to get up and running.