A collection of our articles covering the latest in AI research. Get comprehensive analyses and insights into the cutting-edge AI models and breakthroughs from leading tech companies and research labs.
The company says responsible innovation can’t happen in isolation. By open sourcing its research and resulting models, it hopes to ensure that everyone has equal access.
Improving upon traditional machine vision and perception, this method is designed to help machines perceive and interact with their surroundings in ways that were previously unthinkable.
A new paper takes a closer look at serious open challenges related to RLHF, and emphasizes that relying solely on it for AI alignment is profoundly risky
Across all tasks in the benchmark, Med-PaLM M reached or exceeded state-of-the-art performance, often surpassing specialized models optimized for individual tasks by a wide margin.
The new class of adversarial attacks are capable of circumventing the alignment measures designed to prevent the generation of inappropriate or harmful content in multiple LLMs.
Essentially, the model can comprehend and 'speak robot', translating abstract concepts learned from vast web data into actionable knowledge that informs robot behavior.
With its versatile capabilities and improved performance, CM3leon represents a significant step towards higher-fidelity image generation and understanding, paving the way for enhanced creativity and applications in the metaverse.
This new model is a significant leap forward in AI speech synthesis, demonstrating its versatility and efficiency by outperforming existing models in various tasks, even those it was not specifically trained for.
New research from OpenAI explores how training reward models with process supervision significantly improves mathematical reasoning compared to outcome supervision.
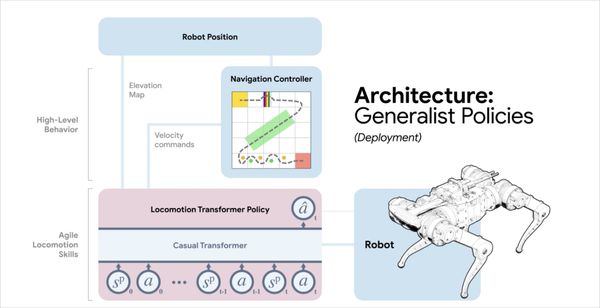
The OP3 Soccer Team at DeepMind has applied deep reinforcement learning to train low-cost humanoid robots to play 1v1 soccer. This research could open doors to more practical applications of reinforcement learning in robotics.